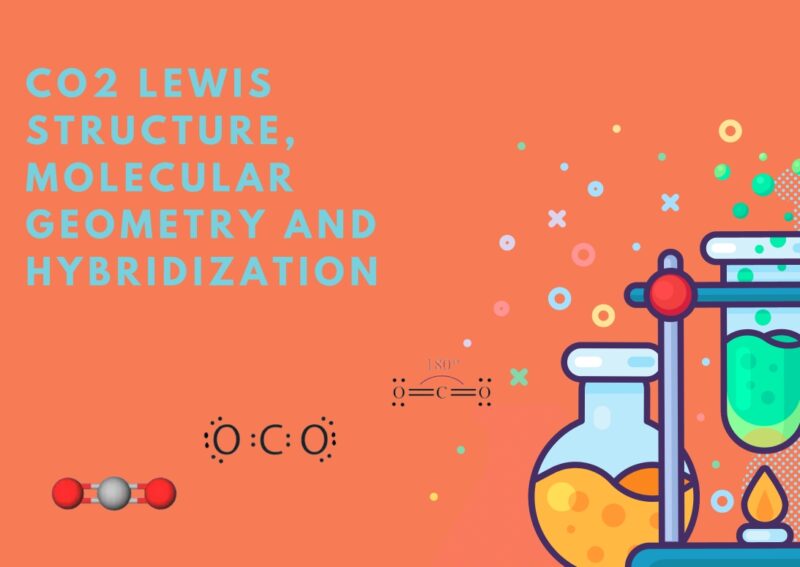
What Is the Molecular Geometry of CO2 – A Simple but Important Molecule

Carbon dioxide, or CO2, is a gas that you’ve probably heard about a lot. It’s what we exhale when we breathe and what plants use during photosynthesis. But have you ever wondered about its shape at the molecular level? In this post, I will walk you through CO2’s molecular geometry. Key Takeaways CO2 has a … Read more